 热点资讯
热点资讯


丝袜美腿快播 深化默契Transformer责任旨趣

什么是Transformer丝袜美腿快播
1、Transformer模子框架
主要由编码器(Encoder)息争码器(Decoder)两部分组成
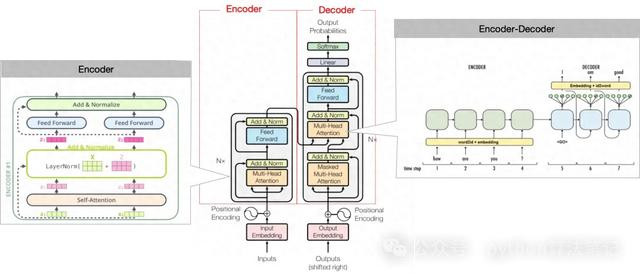
Encoder的主邀功能是将输入升沉为固定维度的向量,它由多个换取的层组成。每层包含两个子层:自细心力层和前馈全贯穿层。自细心力层通过诡计输入中各元素之间的细心力分数,来捕捉元素之间的长程依赖关系;前馈全贯穿层则将每个元素映射到不同的向量空间,以拿获更高档的特征。
Decoder则诳骗Encoder的输出以及议论序列(举例翻译后的句子)算作输入,生成议论序列中每个元素的概率散布。Decoder雷同由多个相似的层组成,每层包括三个子层:自细心力层、编码器-解码器细心力层和前馈全贯穿层。自细心力层和前馈全贯穿层的功能与Encoder中换取,而编码器-解码器细心力层则专注于将Encoder面前位置的输入与Decoder中整个位置进行细心力分数的诡计,以提真金不怕火与议论序列相干的信息。
通盘模子不错概述为以下结构
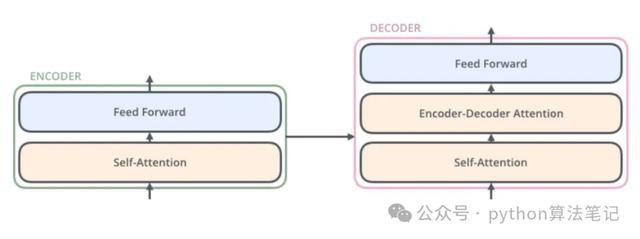
2、编码器(Encoder)
编码器的中枢功能是将输入数据颐养为包含细心力信息的连气儿默示。通过将编码器层堆叠N次,使得每一层齐有契机学习到不同的细心力默示,从而增强Transformer的忖度智力。
编码器的主要组成部分包括:输入镶嵌(Input Embedding)、位置编码(Position Encoding)、多头细心力机制(Multi-Head Attention)以及前馈鸠合(Feed Forward)。
2.1 input Embedding输入镶嵌
偷拍由于诡计机无法径直处理文本信息,因此需要将输入的文本颐养为固定维度的向量默示,从而使其不错被模子所处理。
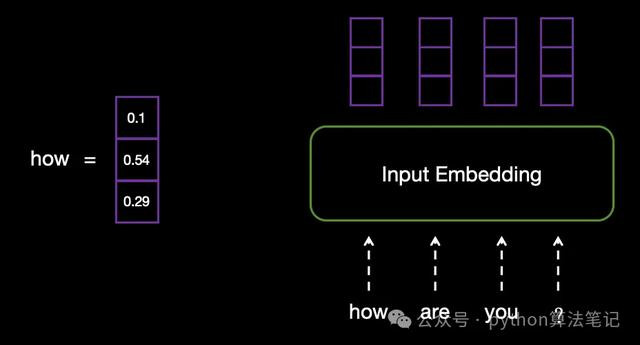
举例,输入文本为“how are you?”,在input Embedding层中,每个单词将被颐养为换取长度的向量。
2.2 Position Encoding位置编码
为何需要位置编码
由于Transformer使用的齐是线性层,编码进程中衰退权贵的位置信息,字词位置的交换履行上仅仅十分于矩阵中行位置的互换。这固然带来了并行诡计的上风,但也消弱了语序信息,因此需要引入位置编码以进行补充。底下咱们来看一个具体的例子。
#假定线性层ww = np.array([1, 2], [3, 4], [5, 6])x = np.array([1, 2, 3], [4, 5, 6], [7, 8, 9])print(x.dot(w))#输出"""[[22, 28] [49, 64] [76, 100]]"""#仅交换输入位置x = np.array([4, 5, 6], [7, 8, 9], [1, 2, 3])print(x.dot(w))#输出"""[[49, 64] [76, 100] [22, 28]]"""
transformer中位置编码
位置编码经常是一组与input Embedding维度换取的向量,通过特定款式生成
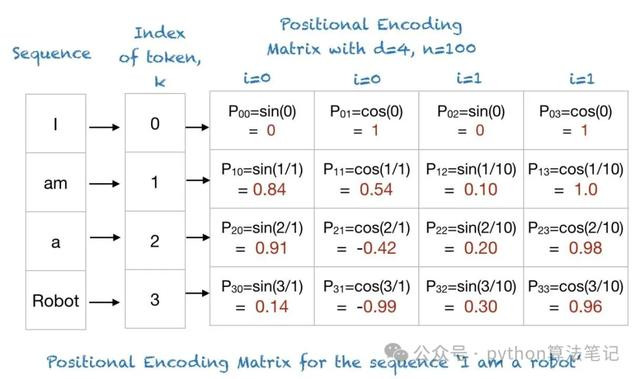
在transformer中,接收正余弦位置编码
其中,是input Embedding镶嵌向量的维度,是单词在序列中的位置,是镶嵌向量中的维度索引 例,输入句子为“I am a robot”,那么其位置编码如下:
2.3 Multi-Head Attention多头细心力机制
细心力机制的产生丝袜美腿快播
细心力机制从内容上宣战东说念主类的选定性细心力机制雷同,中枢议论是从宽阔信息中选定对面前任务议论愈加舛错的信息,它允许模子对输入序列的不同位置分拨不同的权重,以便在处理每个序列元素时关怀最相干的部分
自细心力机制
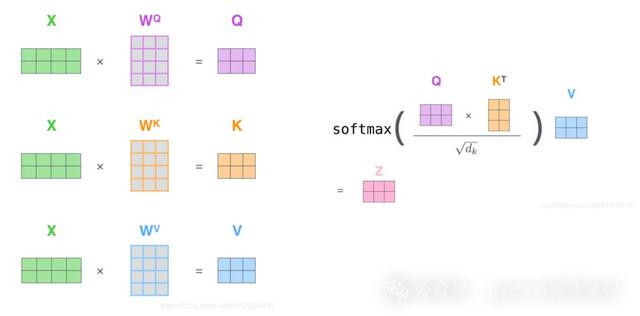
用公式默示为:
注:除以是因为点积数目级增长很大,因此将softmax函数推向梯度极小区域反向传播时导致梯度隐藏而无法学习
如上图,细心力分数诡计分为三步:
1、将一个token embedding区别与三个矩阵作念矩阵乘后得到这个token对应的三个向量
2、为了找到token与其他token的关怀关系,将token的向量与其他整个token的向量作念内积,除以后得到细心力分数
3、过softmax将分数归一化到[0,1]之间,那么对于不太需要关怀的token权重就会很小
多头细心力机制
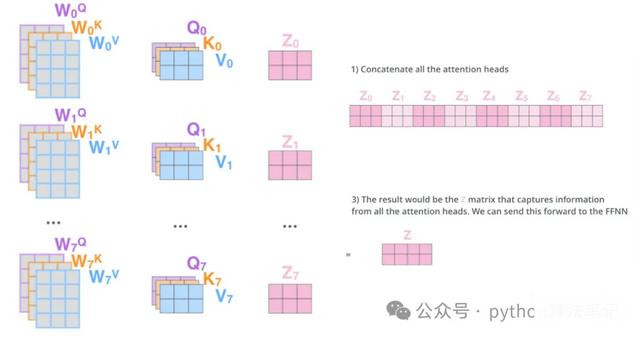
多头细心力机制是在自细心力机制的基础演出变而来的,它是一种自细心力机制的变体,主义是莳植模子的抒发智力和泛化智力。该机制通过多个独处的细心力头来区别诡计细心力权重,最终将这些欺压加权乞降,从而得回愈加丰富的默示。
2.4 残差贯穿
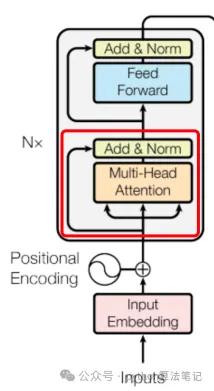
残差贯穿指的是将多头细心力机制的输出向量与原始输入向量相加,然后再进行层归一化处理。
2.5 Norm层归一化

在Transformer中,主要接收层归一化而非批归一化,这么不错有用幸免历练进程中出现的梯度隐藏问题,从而莳植模子的雄厚性。
①.为何使用层归一化:在当然话语处理任务中,输入序列的长度经常是变化的。层归一化是针对单个样本内的整个特征进行归一化,因此它大概较好地处理可变长度的情况。
②.何时使用:层归一化经常在残差贯穿之后使用。在Transformer模子中,每个子层齐配置有一个残差贯穿,自后紧接着进行层归一化处理。
2.6 Feed Forward前馈鸠合层
在Transformer中,前馈鸠合被称为点对点前馈神经鸠合(Position-wise Feed-Forward Networks,简称FFN)。它实质上由两个全贯穿层组成:第一个层将输入的维度膨大(举例,从512维加多到2048维),并通过激活函数(经常使用ReLU或GELU)进行处理;第二个层则将膨大后的输出缩减回原始维度(比如,从2048维缩减回512维)。
完成前馈鸠合层的处理后,会进行残差贯穿并随后进行层归一化。
3、解码器(Decoder)
解码器的主邀功能是生成文本序列。其结构主要由以下几个部分组成:
具有掩码的多头细心力机制(Masked Multi-Head Attention):用于确保在生成进程中,只辩论面前及之前的输入,驻防信息清楚。
多头细心力机制(Multi-Head Attention):用于关怀编码器输出的不同部分,以整合高下文信息。
前馈鸠合(Feed Forward):对每个位置的默示进行进一步处理,以提真金不怕火更复杂的特征。
分类器(Classifier):将最终的编码默示颐养为议论文本的词汇散布,生成最终的输出。
3.1 Output Embedding
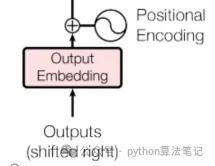
在解码器中,议论序列率先通过镶嵌层颐养为密集的向量默示。接着,通过位置编码将序列中的位置信息添加到这些向量中,这些处理后的向量将算作解码器的输入,供模子历练使用。
3.2 Masked Multi-Head Attention具有掩码的多头细心力机制
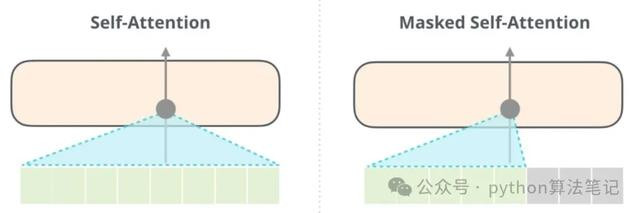
在自细心力机制中,面前词与其他词之间的关系会被诡计。然则,在使用解码器生成序列时,议论是忖度面前位置的单词,这就条目模子只可造访该位置之前的信息,而无法使用面前位置之后的信息,以驻防信息清楚。因此,需要选定一些要道来遮蔽背面的信息。在Transformer中,这主要通过应用掩码(Mask)操作来结束。
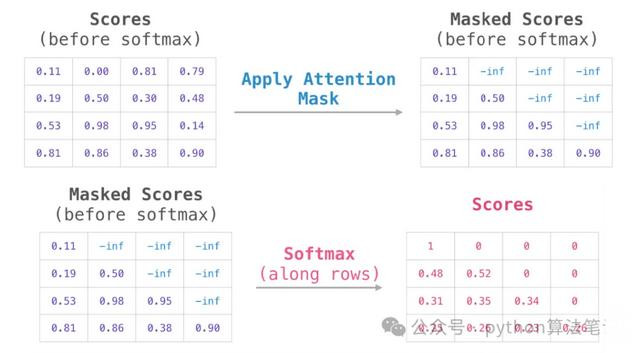
为幸免解码器获取曩昔的信息,在已得回的细心力分数矩阵上添加一个掩码矩阵,使得掩码位置的细心力分数变为负无尽大,从而得到Masked Scores。这么,在经过softmax函数处理后,对于“面前词”的“曩昔词”的细心力得分将变为0,即不会造访到曩昔的信息。
3.3 Multi-Head Attention多头细心力机制
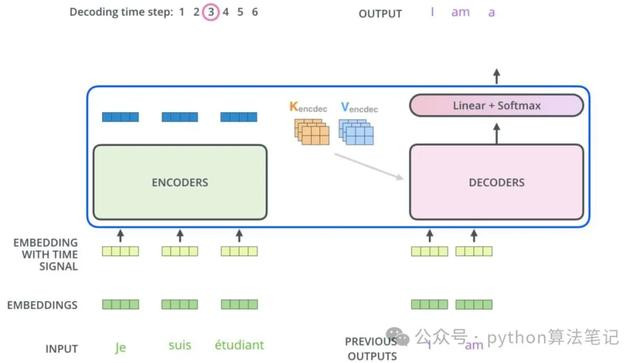
这里的多头细心力机制和编码器部分旨趣换取,不外它的输入来自于编码器,主义是将解码器面前生成的序列与经过编码器处理的原始输入序列关联起来,以生成下一个议论词。
3.4 Feed Forward前馈鸠合
参考Encoder部分的Feed Forward
3.5 分类器
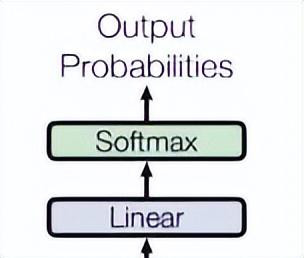
临了,由一个线性层和一个softmax得到面前词概率
3.6 生成序列住手
在模子输出""时住手生成,至此通盘Transformer模子的各个部分照旧无缺拆解。该模子具体处罚了以下几个舛错问题:
长距离依赖关系问题:传统的RNN在处理长文本时,容易冷漠序列中的远距离依赖。Transformer诳骗自细心力机制,大概为序列中不同位置的每个元素分拨不同的遑急性,从而有用捕捉长距离的依赖关系。
并行诡计问题:传统RNN的历练进程需要按次列规则一一进行,因而无法结束并行诡计,导致诡计成果低下。Transformer引入了编码器-解码器框架,使得不错在输入序列上进行编码,并在输出序列上进行解码,从而结束并行诡计,权贵提高了模子历练的速率。
特征抽取问题:通过自细心力机制和多层神经采鸠合构,Transformer大概从输入序列中高效提真金不怕火丰富的特征信息,从而为后续任务提供更强的相沿。
咱们肯定东说念主工智能为平庸东说念主提供了一种“增强器用”,并用功于共享全方向的AI学问。在这里,您不错找到最新的AI科普著作、器用评测、莳植成果的隐私以及行业洞悉。
接待关怀“福大大架构师逐日一题”丝袜美腿快播,让AI助力您的曩昔发展。